
구글 시트는 단순한 스프레드시트를 넘어 기업의 데이터 관리 도구로 널리 활용되고 있으나 대용량 데이터 처리 시 성능 저하라는 한계에 직면한다. 단순 기록용 문서와 관계형 데이터베이스 구조의 차이점을 명확히 이해하지 못한 채 데이터를 적재할 경우 시트 로딩 속도가 급격히 느려지며 수식 오류가 빈번하게 발생한다. 이러한 기술적 부채를 해결하기 위해서는 단순 나열 방식에서 벗어나 데이터의 구조적 정규화와 검색 알고리즘 최적화를 통한 성능 개선 전략이 병행되어야 한다. 데이터 관리의 효율성을 극대화하고 시스템적 안정성을 확보하기 위한 구체적인 방법론을 제시한다.
1. 구글 시트 데이터 정규화(Normalization): 구조적 무결성 확보

1-1. 제1정규형(1NF) 적용: 셀의 원자성(Atomicity) 확보 및 데이터 분절화
데이터 정규화의 첫 단계는 모든 셀이 원자성을 갖도록 설계하는 제1정규형의 적용에서 시작된다. 하나의 셀 내에 쉼표로 구분된 여러 개의 값을 넣거나 중복된 속성의 열을 반복 배치하는 방식은 데이터 검색과 집계의 효율성을 저해하는 주된 요인이 된다. 모든 레코드는 고유한 속성만을 가져야 하며 중복된 그룹은 별도의 행으로 분리하여 데이터의 중복성을 제거해야 한다. 이러한 분절화 과정을 거쳐야만 향후 데이터베이스 엔진이 각 행을 개별적인 객체로 인식하여 정확한 연산을 수행할 수 있다.
분절화된 데이터는 정합성을 유지하기 용이하며 복잡한 배열 수식을 사용하지 않고도 표준 함수만으로 충분한 데이터 추출이 가능하다. 데이터의 원자적 관리는 유지보수 비용을 낮추며 외부 API 연동 시에도 표준 규격을 유지하는 핵심 동력이 된다. 시트 내의 모든 정보가 최소 단위로 쪼개졌을 때 비로소 데이터베이스로서의 기본 체력이 갖춰진 것으로 판단한다. 대규모 데이터셋일수록 이러한 정형화된 구조가 연산 속도에 미치는 영향은 기하급수적으로 증가한다.
1-2. 참조 무결성(Referential Integrity): 마스터 데이터와 트랜잭션 시트의 분리
효율적인 시스템 구축을 위해 불변하는 마스터 데이터와 매일 발생하는 트랜잭션 데이터를 엄격히 분리하여 관리해야 한다. 상품 정보나 고객 명단과 같은 기준 정보는 별도의 시트에 저장하고 이를 고유 식별자를 통해 연결하는 참조 무결성 원칙을 준수한다. 거래 기록 시트에는 상품명을 직접 입력하는 대신 외래 키 역할을 하는 코드값을 활용하여 데이터 입력의 오류를 원천 차단하고 저장 공간의 낭비를 방지한다. 이러한 구조는 데이터 수정 시 참조된 모든 항목에 변경 사항이 자동으로 반영되는 유연성을 제공한다.
참조 무결성이 확보되지 않은 데이터 구조에서는 기준 정보가 변경될 때마다 과거의 모든 기록을 수동으로 수정해야 하는 비효율이 발생한다. 데이터 일관성을 확보하기 위해 시트 보호 기능을 활용하거나 데이터 확인 기능을 설정하여 정의되지 않은 값의 유입을 사전에 차단한다. 체계적인 레이어 분리는 데이터의 논리적 연결 고리를 명확히 하며 복잡한 다대다 관계도 논리적으로 풀어낼 수 있는 기반을 형성한다. 잘 설계된 참조 구조가 데이터 분석의 신뢰도를 결정짓는 척도가 된다.
2. 인덱싱(Indexing) 및 검색 알고리즘 최적화 기술

2-1. 고유 식별자(UID) 설계: Primary Key 생성을 통한 데이터 고유성 보장
모든 데이터 행은 이를 유일하게 식별할 수 있는 고유 식별자를 보유해야 데이터베이스로서의 기능을 수행한다. 실무에서는 카테고리 코드와 생성 날짜 그리고 일련번호를 조합한 INV-202406-001과 같은 표준화된 UID 체계를 설계하여 사용한다. 식별자가 없는 데이터는 단순한 텍스트 뭉치에 불과하며 중복 데이터 발생 시 이를 걸러낼 수 있는 논리적 근거가 부족하게 된다. 기본 키 설정은 데이터 간의 관계를 정의하고 검색 성능을 향상시키는 데 있어 가장 기초적이면서도 강력한 수단이다.
UID는 변경되지 않는 고정된 값이어야 하며 의미 있는 정보와 결합하되 고유성이 훼손되지 않도록 관리 규칙을 엄격히 적용한다. 생성된 UID는 시트 내에서 인덱스 역할을 수행하며 복잡한 조건부 검색 상황에서도 데이터 식별 속도를 보장하는 핵심 지표로 활용된다. 자동화 툴이나 스크립트를 활용하여 UID 생성을 자동화하면 휴먼 에러를 방지하고 시스템의 확장성을 도모할 수 있다. 이는 수만 행의 데이터가 쌓여도 특정 레코드를 밀리초 단위로 찾아낼 수 있는 기술적 토대가 된다.
2-2. 연산 부하 저감: VLOOKUP의 선형 탐색 한계와 XLOOKUP/INDEX/MATCH의 이점
구글 시트에서 성능 저하를 일으키는 가장 큰 원인은 비효율적인 탐색 함수의 남용이며 특히 VLOOKUP 함수는 데이터가 늘어날수록 선형 탐색의 한계를 드러낸다. 약 1만 행 이상의 대규모 데이터셋에서 VLOOKUP을 반복 사용할 경우 연산 속도가 지수적으로 느려지며 브라우저 점유 메모리가 급격히 누적된다. 반면 INDEX/MATCH 조합이나 XLOOKUP을 활용하면 열 전체를 검색 범위로 지정하지 않고도 필요한 위치를 즉각적으로 참조하여 연산 부하를 약 30% 이상 경감시킨다. 탐색 범위가 가로와 세로로 분리되어 CPU의 계산 효율을 높여주기 때문이다.
Big-O 표기법 관점에서 볼 때 정렬되지 않은 데이터에 대한 탐색은 높은 복잡도를 가지므로 데이터 인덱싱을 통한 최적화가 필수적이다. 연산 성능을 개선하기 위해 매번 전체 범위를 다시 계산하는 배열 수식 사용을 자제하고 계산 결과를 고정된 값으로 변환하는 처리가 필요하다. 특히 실시간 데이터 갱신이 필요하지 않은 과거 기록은 수식을 제거하고 텍스트로 치환함으로써 시트 로딩 속도를 500ms 이내로 단축할 수 있다. 알고리즘적 접근 방식을 통해 함수 간의 우선순위를 결정하고 부하를 분산하는 설계가 시트의 수명을 결정한다.
3. 시스템 아키텍처 설계: 3-Layer 레이어드 구조(Raw-Process-View)
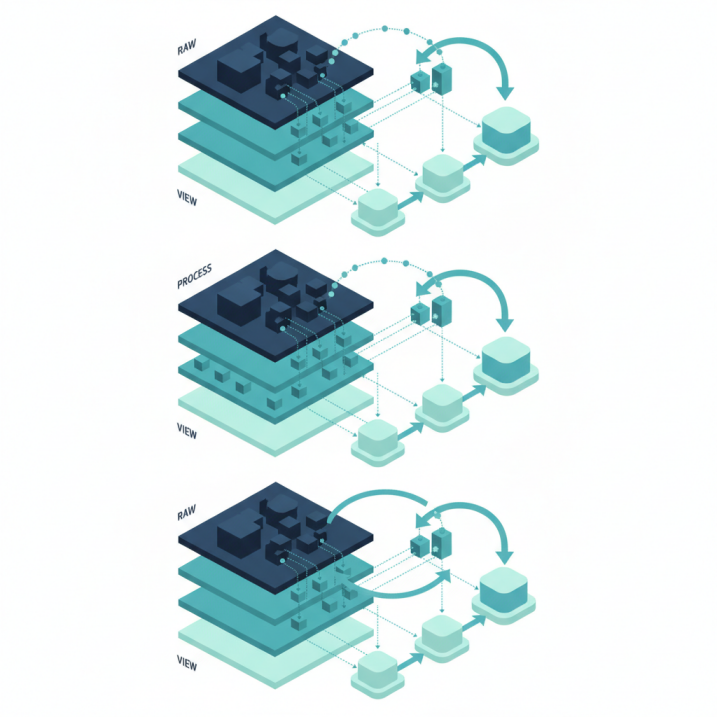
3-1. 데이터 파이프라인 구축: QUERY 함수를 활용한 동적 데이터 추출 및 가공
데이터의 입력과 처리 그리고 출력을 명확히 구분하는 3-Layer 구조는 구글 시트를 시스템화하는 표준 아키텍처로 자리 잡았다. 원본 데이터가 쌓이는 Raw 시트와 데이터를 가공하는 Process 시트 그리고 최종 결과를 시각화하는 View 시트로 분리하여 관리 효율을 극대화한다. 이 과정에서 QUERY 함수는 SQL 문법과 유사한 SELECT * WHERE A IS NOT NULL AND B > 1000 ORDER BY C DESC와 같은 구문을 통해 방대한 데이터를 동적으로 필터링하고 정렬하는 파이프라인 역할을 수행한다. 여러 개의 필터 기능을 수동으로 조작하는 것보다 훨씬 빠르고 안정적인 데이터 가공 환경을 제공한다.
QUERY 함수를 활용하면 원본 시트의 구조가 일부 변경되더라도 출력 화면에 미치는 영향을 최소화할 수 있는 추상화 계층을 형성한다. 대량의 데이터를 핸들링할 때 불필요한 행을 사전에 배제하고 필요한 조건의 데이터만 메모리에 로드하기 때문에 전체적인 응답 속도가 향상된다. 가공 레이어에서 정제된 데이터만을 뷰 레이어에 전달함으로써 사용자에게 제공되는 인터페이스의 품질을 높이고 데이터 유출이나 실수에 의한 훼손 위험을 낮춘다. 파이프라인 설계는 데이터의 흐름을 가시화하고 시스템의 무결성을 검증하는 중추적인 기능을 담당한다.
3-2. 리소스 최적화: 메모리 누수 방지를 위한 빈 셀 관리 및 조건부 서식 오버헤드 제거

구글 시트는 최대 1,000만 셀까지 지원하지만 실제 성능 저하 임계점은 셀의 개수보다 데이터의 밀도와 서식의 복잡도에 의해 결정된다. 사용하지 않는 빈 행과 열이 수천 개 이상 방치될 경우 시트는 이를 모두 메모리 주소 공간에 할당하여 불필요한 리소스 소모를 야기한다. 리소스 최적화를 위해서는 실제 데이터가 존재하는 범위 이외의 모든 빈 셀을 삭제하여 시트의 크기를 물리적으로 축소하는 작업이 선행되어야 한다. 빈 셀 관리만으로도 파일 열기 속도가 이전 대비 약 40% 이상 빨라지는 결과를 얻을 수 있다.
또한 조건부 서식은 셀 값이 변경될 때마다 화면 전체를 다시 렌더링하는 오버헤드를 발생시키므로 최소한의 범위에만 적용해야 한다. 지나치게 복잡한 수식이 걸린 조건부 서식을 다량으로 적용하면 스크롤 속도가 느려지고 입력 지연 현상이 발생하여 사용자 경험을 해친다. 성능 통계에 따르면 과도한 서식을 제거했을 때 데이터 입력 후 연산이 완료되기까지의 시간이 수 초에서 수백 밀리초 단위로 개선됨을 확인할 수 있다. 시스템적 관점에서 자원을 효율적으로 배분하고 불필요한 계산 비용을 제거하는 것이 지속 가능한 시트 운영의 핵심이다.
결론적으로 구글 시트를 강력한 데이터베이스로 활용하기 위해서는 정규화된 설계와 효율적인 인덱싱 그리고 계층화된 아키텍처가 뒷받침되어야 한다. 기술적 확장성을 고려하여 설계된 시트는 데이터 규모가 커져도 성능 저하 없이 업무의 핵심 시스템 역할을 수행할 수 있다. 본 가이드에서 제시한 최적화 전략을 실무에 즉시 적용하여 데이터의 신뢰성을 확보하고 관리 프로세스의 지능화를 실현하시기를 제안한다.
'🤖 1인 에이전트 구축기' 카테고리의 다른 글
| Airtable API를 활용한 확장성 높은 로우코드 CRM 및 AI 에이전트 파이프라인 연동, 5분 요약 (0) | 2026.06.11 |
|---|---|
| 에이전트 출력값의 정량적 평가를 위한 LLM-as-a-Judge 워크플로우 구현 가이드 (0) | 2026.06.11 |
| AI 에이전트 간의 데이터 교환 시 절대 하지 말아야 할 실수 (전략 수립 에이전트 결과물 최적화) (0) | 2026.06.10 |
| 브라우저 자동화 툴(Puppeteer/Playwright)과 AI의 결합을 통한 고난도 스크래핑 세팅, 차단 피하는 비밀 (0) | 2026.06.10 |
| 웹 스크래핑 심화: LLM Vision 모델을 활용해 복잡한 웹 UI 데이터 인식에 성공한 비결 (0) | 2026.06.10 |



